3.1. Characteristics and limits of the relational OLAP system¶
A relational OLAP system is the most popular method of collecting and managing data. The figure below indicates an example of the star schema structure, the most frequently used structure in a relational OLAP system.
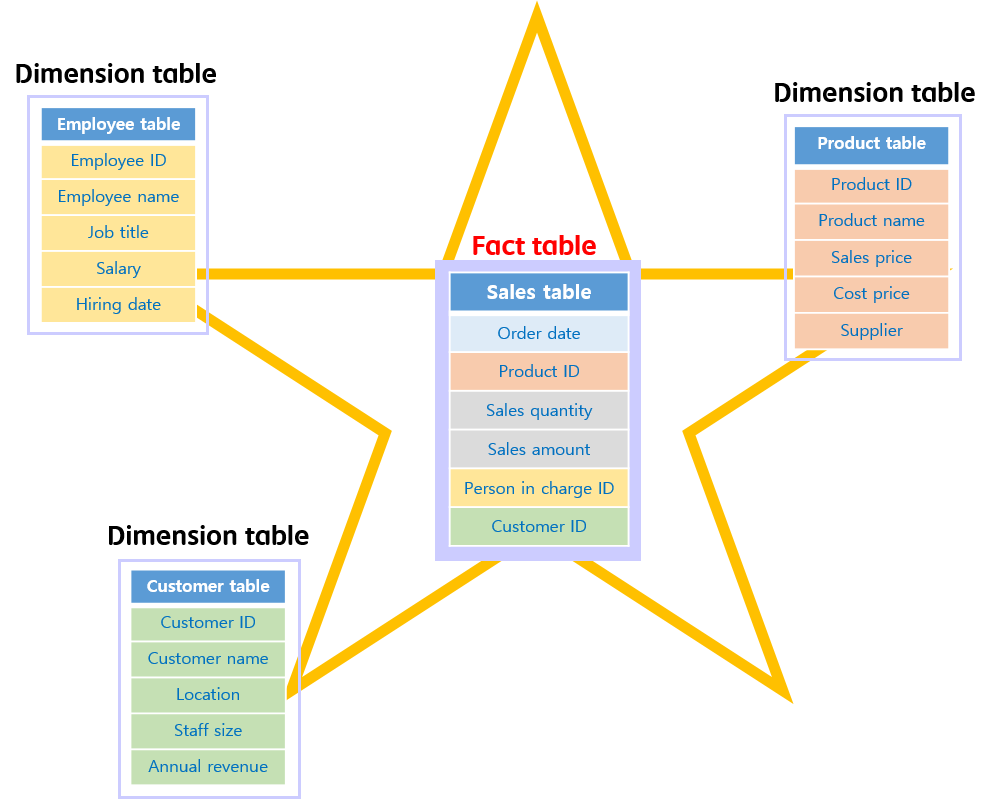
As shown in the figure, a basic star schema is composed of many dimension tables and a small number of fact tables.
- Detailed data on each dimension of the schema is stored in the dimension table. In the example shown in the figure above, the three dimension tables each contain data relating to the product, the employee, and the customer. Each of these is called a “dimension” because you can use them as a standard for data classification (e.g., quantity sold by each employee and quantity purchased by each customer).
- In the fact table, a record containing the details of the event is added one at a time whenever a new event occurs. In this case, a connection is made to each dimension table using the reference ID as mediator.
The figure below summarizes an example of simple table based on the schema structure above to aid in understanding.
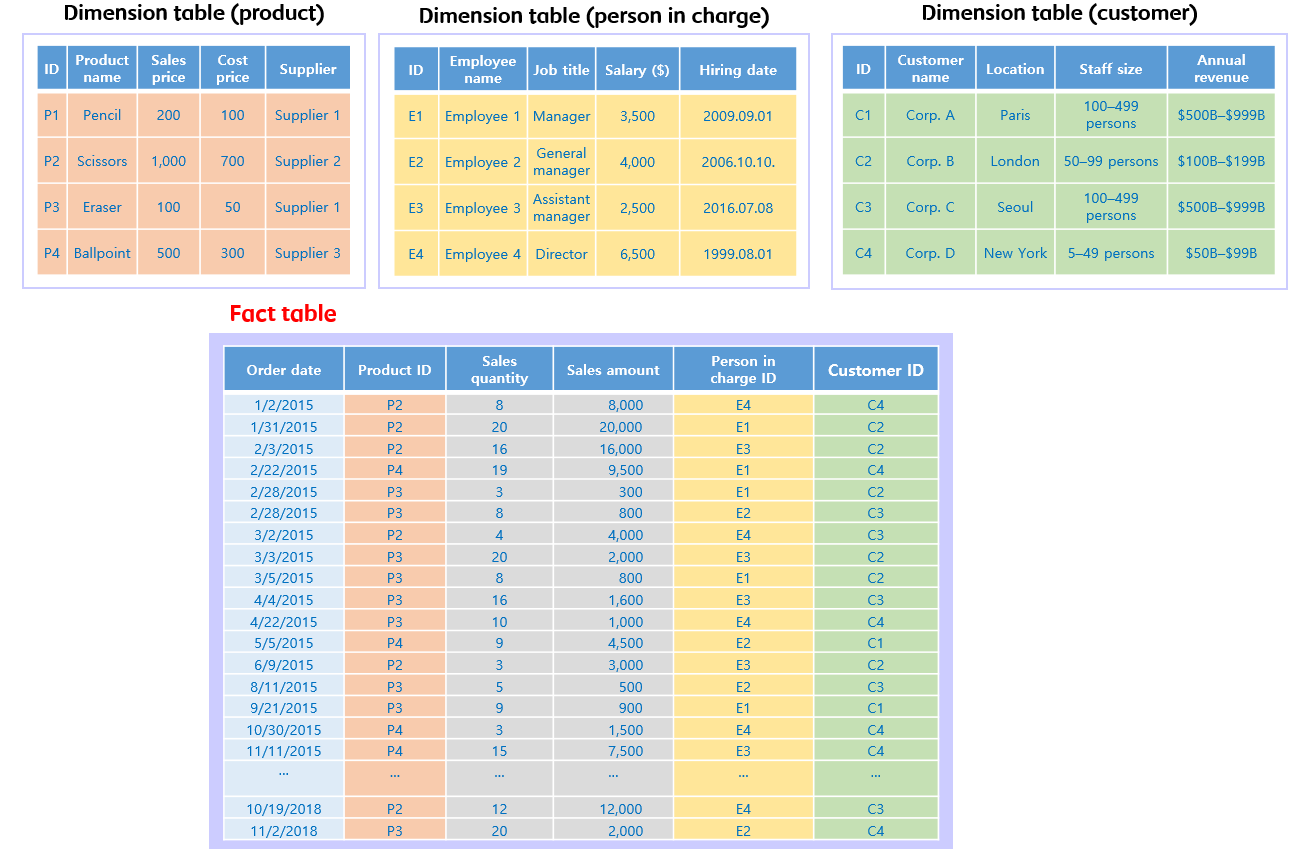
Although the products sold, the sales staff, and the customer making the purchase are recorded as a simple ID in each record of the fact table, each of these IDs can be used for searching detailed information if necessary, since they are connected with a unique dimension table. For example, if we search the product table, the P2 product in the first record indicates that the applicable product type is pencil, the unit price for sale is 200 KRW, the unit price for supply is 100 KRW, and the supplier is Supplier 1. Using such data collection method offers the advantage of being able to use the storage area effectively by storing only the minimum amount of data in the fact table.
When trying to analyze data stacked this way, however, the reference ID of the relational OLAP actually becomes the cause of decreasing data accessibility and speed. This is because the original data connected to all of the reference IDs included in each record used for analysis in the fact table must be loaded one by one into each dimension table. If there are 100,000 records for analysis, and 4 reference IDs per record, this must go through a data loading process of 100,000 x 4 times, causing that amount of load on the data processing device. Moreover, there are only a limited number of skilled people who understand the schema structure of the database properly, meaning only they are able to use such a data load query.
The multi-dimensional OLAP system described in the next section overcomes the limitations of such a legacy structure by saving all data into one or a small number of tables.