Note
Click here to download the full example code
공간 변형기 네트워크(Spatial Transformer Networks) 튜토리얼¶
- Author: Ghassen HAMROUNI
- 번역: 황성수

이 튜토리얼에서 공간 변형 네트워크(Spatial Transformer Networks, STN)로 불리는 시각 어텐션 메카니즘을 이용한 네트워크 사용 방법을 배웁니다. DeepMind paper 에서 STN에 관해 더 많은 것을 읽을 수 있습니다.
STN은 어떤 공간 변형에도 미분 가능한 어텐션의 일반화입니다. STN은 신경망이 모델의 기하하적 불변성을 강화하기 위해서 어떻게 입력 이미지 공간 변형을 수행해야 하는지 배우게 합니다. 예를 들어서 이미지의 관심 영역을 잘르고 크기를 조정하고 방향을 수정할 수 있습니다. CNN이 회전과 크기 그리고 더 일반적인 아핀(affine) 변형에 불변하지 않기 때문에 (민감하기 때문에) 이것은 매우 유용한 메카니즘 입니다.
STN의 가장 좋은 점 중 하나는 거의 수정하지 않고 기존의 CNN에 간단히 연결할 수 있는 점 입니다.
# 라이센스: BSD
# Author: Ghassen Hamrouni
from __future__ import print_function
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy as np
plt.ion() # interactive mode
데이터 로딩¶
이 포스트에서 고전적인 MNIST 데이터 세트를 실험합니다. STN으로 보강된 표준 CN(convolutional network)을 사용합니다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 학습 데이터
train_loader = torch.utils.data.DataLoader(
datasets.MNIST(root='.', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])), batch_size=64, shuffle=True, num_workers=4)
# 테스트 데이터
test_loader = torch.utils.data.DataLoader(
datasets.MNIST(root='.', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])), batch_size=64, shuffle=True, num_workers=4)
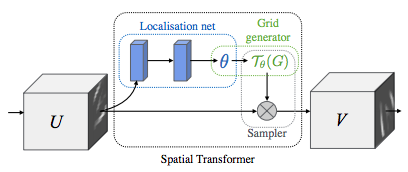
공간 변형 네트워크 설명¶
STN은 3가지 주요 구성 요소로 요약됩니다:
- 위치 결정 네트워크(localization network)는 변형 파라미터를 회귀시키는 일반적인 CNN 입니다. 변형은 이 데이터셋에 명시적으로 학습되지 않으며 네트워크는 전체 정확도를 향상하는 공간 변형을 자동으로 학습합니다.
- 그리드 생성기(grid generator)는 출력 이미지로의 각 픽셀에 대응하는 입력 이미지에서 좌표 그리드를 생성한다.
- 샘플러는 변형의 파라미터를 사용하여 입력 이미지에 적용합니다.
Note
affine_grid 및 grid_sample 모듈이 포함 된 PyTorch의 최신 버전이 필요합니다.
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
# Spatial transformer localization-network
self.localization = nn.Sequential(
nn.Conv2d(1, 8, kernel_size=7),
nn.MaxPool2d(2, stride=2),
nn.ReLU(True),
nn.Conv2d(8, 10, kernel_size=5),
nn.MaxPool2d(2, stride=2),
nn.ReLU(True)
)
# Regressor for the 3 * 2 affine matrix
self.fc_loc = nn.Sequential(
nn.Linear(10 * 3 * 3, 32),
nn.ReLU(True),
nn.Linear(32, 3 * 2)
)
# Initialize the weights/bias with identity transformation
self.fc_loc[2].weight.data.zero_()
self.fc_loc[2].bias.data.copy_(torch.tensor([1, 0, 0, 0, 1, 0], dtype=torch.float))
# Spatial transformer network forward function
def stn(self, x):
xs = self.localization(x)
xs = xs.view(-1, 10 * 3 * 3)
theta = self.fc_loc(xs)
theta = theta.view(-1, 2, 3)
grid = F.affine_grid(theta, x.size())
x = F.grid_sample(x, grid)
return x
def forward(self, x):
# transform the input
x = self.stn(x)
# Perform the usual forward pass
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
model = Net().to(device)
모델 학습¶
이제 SGD 알고리즘을 사용하여 모델을 학습시켜 봅시다. 네트워크는 감독 방식으로 분류 작업을 학습하고 있습니다. 동시에 모델은 STN을 자동으로 end-to-end 방식으로 학습합니다.
optimizer = optim.SGD(model.parameters(), lr=0.01)
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 500 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
#
# MNIST에서 STN의 성능을 측정하는 간단한 테스트 절차.
#
def test():
with torch.no_grad():
model.eval()
test_loss = 0
correct = 0
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
# sum up batch loss
test_loss += F.nll_loss(output, target, size_average=False).item()
# get the index of the max log-probability
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'
.format(test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
STN 결과 시각화¶
이제 학습 된 비주얼 어텐션 메커니즘의 결과를 검사 할 것입니다.
훈련 도중 변형을 시각화하기 위해 작은 헬퍼 함수를 정의합니다.
def convert_image_np(inp):
"""Convert a Tensor to numpy image."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
return inp
# 학습 후에 공간 변형 레이어의 출력을 시각화하기 위해 STN을
# 사용하여 입력 이미지 배치와 해당 변형 배치를 시각화합니다.
def visualize_stn():
with torch.no_grad():
# Get a batch of training data
data = next(iter(test_loader))[0].to(device)
input_tensor = data.cpu()
transformed_input_tensor = model.stn(data).cpu()
in_grid = convert_image_np(
torchvision.utils.make_grid(input_tensor))
out_grid = convert_image_np(
torchvision.utils.make_grid(transformed_input_tensor))
# Plot the results side-by-side
f, axarr = plt.subplots(1, 2)
axarr[0].imshow(in_grid)
axarr[0].set_title('Dataset Images')
axarr[1].imshow(out_grid)
axarr[1].set_title('Transformed Images')
for epoch in range(1, 20 + 1):
train(epoch)
test()
# 일부 입력 배치에서 STN 변형 시각화
visualize_stn()
plt.ioff()
plt.show()

Out:
Train Epoch: 1 [0/60000 (0%)] Loss: 2.297115
Train Epoch: 1 [32000/60000 (53%)] Loss: 0.937764
Test set: Average loss: 0.2384, Accuracy: 9314/10000 (93%)
Train Epoch: 2 [0/60000 (0%)] Loss: 0.444883
Train Epoch: 2 [32000/60000 (53%)] Loss: 0.276500
Test set: Average loss: 0.1177, Accuracy: 9657/10000 (97%)
Train Epoch: 3 [0/60000 (0%)] Loss: 0.213871
Train Epoch: 3 [32000/60000 (53%)] Loss: 0.499969
Test set: Average loss: 0.1109, Accuracy: 9650/10000 (96%)
Train Epoch: 4 [0/60000 (0%)] Loss: 0.156239
Train Epoch: 4 [32000/60000 (53%)] Loss: 0.286783
Test set: Average loss: 0.0782, Accuracy: 9769/10000 (98%)
Train Epoch: 5 [0/60000 (0%)] Loss: 0.310013
Train Epoch: 5 [32000/60000 (53%)] Loss: 0.197604
Test set: Average loss: 0.0769, Accuracy: 9770/10000 (98%)
Train Epoch: 6 [0/60000 (0%)] Loss: 0.130109
Train Epoch: 6 [32000/60000 (53%)] Loss: 0.243406
Test set: Average loss: 0.0605, Accuracy: 9801/10000 (98%)
Train Epoch: 7 [0/60000 (0%)] Loss: 0.130796
Train Epoch: 7 [32000/60000 (53%)] Loss: 0.098661
Test set: Average loss: 0.0676, Accuracy: 9790/10000 (98%)
Train Epoch: 8 [0/60000 (0%)] Loss: 0.214395
Train Epoch: 8 [32000/60000 (53%)] Loss: 0.270841
Test set: Average loss: 0.0793, Accuracy: 9766/10000 (98%)
Train Epoch: 9 [0/60000 (0%)] Loss: 0.366239
Train Epoch: 9 [32000/60000 (53%)] Loss: 0.081371
Test set: Average loss: 0.0519, Accuracy: 9842/10000 (98%)
Train Epoch: 10 [0/60000 (0%)] Loss: 0.102711
Train Epoch: 10 [32000/60000 (53%)] Loss: 0.113266
Test set: Average loss: 0.0558, Accuracy: 9825/10000 (98%)
Train Epoch: 11 [0/60000 (0%)] Loss: 0.374193
Train Epoch: 11 [32000/60000 (53%)] Loss: 0.055501
Test set: Average loss: 0.0472, Accuracy: 9852/10000 (99%)
Train Epoch: 12 [0/60000 (0%)] Loss: 0.067803
Train Epoch: 12 [32000/60000 (53%)] Loss: 0.040589
Test set: Average loss: 0.0568, Accuracy: 9831/10000 (98%)
Train Epoch: 13 [0/60000 (0%)] Loss: 0.080509
Train Epoch: 13 [32000/60000 (53%)] Loss: 0.390123
Test set: Average loss: 0.0410, Accuracy: 9875/10000 (99%)
Train Epoch: 14 [0/60000 (0%)] Loss: 0.021992
Train Epoch: 14 [32000/60000 (53%)] Loss: 0.147132
Test set: Average loss: 0.0442, Accuracy: 9861/10000 (99%)
Train Epoch: 15 [0/60000 (0%)] Loss: 0.017601
Train Epoch: 15 [32000/60000 (53%)] Loss: 0.089066
Test set: Average loss: 0.0413, Accuracy: 9879/10000 (99%)
Train Epoch: 16 [0/60000 (0%)] Loss: 0.098863
Train Epoch: 16 [32000/60000 (53%)] Loss: 0.161777
Test set: Average loss: 0.0419, Accuracy: 9872/10000 (99%)
Train Epoch: 17 [0/60000 (0%)] Loss: 0.126542
Train Epoch: 17 [32000/60000 (53%)] Loss: 0.160993
Test set: Average loss: 0.0462, Accuracy: 9866/10000 (99%)
Train Epoch: 18 [0/60000 (0%)] Loss: 0.077914
Train Epoch: 18 [32000/60000 (53%)] Loss: 0.117342
Test set: Average loss: 0.0658, Accuracy: 9788/10000 (98%)
Train Epoch: 19 [0/60000 (0%)] Loss: 0.165278
Train Epoch: 19 [32000/60000 (53%)] Loss: 0.127581
Test set: Average loss: 0.0334, Accuracy: 9886/10000 (99%)
Train Epoch: 20 [0/60000 (0%)] Loss: 0.089877
Train Epoch: 20 [32000/60000 (53%)] Loss: 0.101371
Test set: Average loss: 0.0432, Accuracy: 9881/10000 (99%)
Total running time of the script: ( 2 minutes 16.998 seconds)